Talk RL Podcast
Interview & Research Overview
Conversation with Robin Chauhan about my research. Great place to start for a big picture overview.

I am a researcher at OpenAI working to solve artificial intelligence. My research focus is on decision making under uncertainty, aka reinforcement learning. I am particularly interested in problems around exploration: learning to make good decisions when you are uncertain about the world. I use these insights to improve ChatGPT to develop the "data flywheel". You can learn more in this podcast interview.
Before OpenAI, I was a staff research scientist at Google DeepMind. I started in London, and then moved to SF to help build the efficient agent team. I completed my Ph.D. at Stanford University advised by Benjamin Van Roy. My thesis Deep Exploration via Randomized Value Functions won second place in the national Dantzig dissertation award.
Before Stanford, I studied maths at Oxford University, and worked for J.P.Morgan as a credit derivatives strategist in London and New York. If you want to get the latest scoop then check out my twitter.
For full list see Google Scholar.

Interview & Research Overview
Conversation with Robin Chauhan about my research. Great place to start for a big picture overview.

NeurIPS 2023 Spotlight
Scalable uncertainty in deep learning. Better performance than an ensemble of size=100 at cost <2 particles.

NeurIPS 2022 Spotlight
Benchmark for the prediction quality of approximate posterior inference in deep learning. Popular Bayesian deep learning approaches do not do well.

JMLR 2019
Journal paper that embodies the best pieces of research from my PhD and other pieces of work from our group.

Foundations and Trends in Machine Learning 2020
A thoughtful tutorial around Thompson sampling to balance exploration with exploitation.
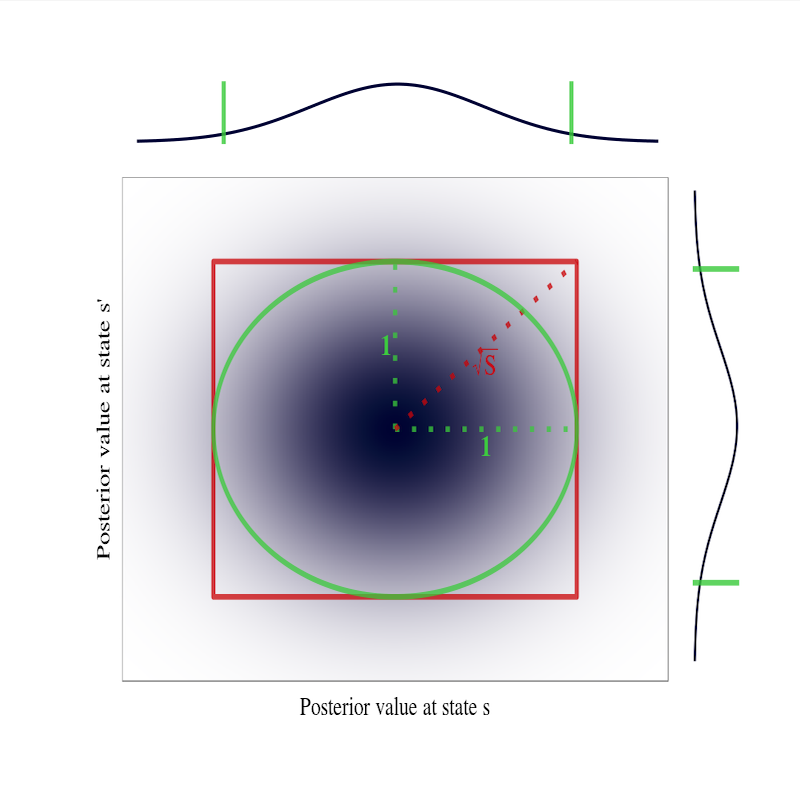
ICML 2016 (full oral), EWRL 2016
Computational results show PSRL dramatically outperforms UCRL2. We provide insight into why.
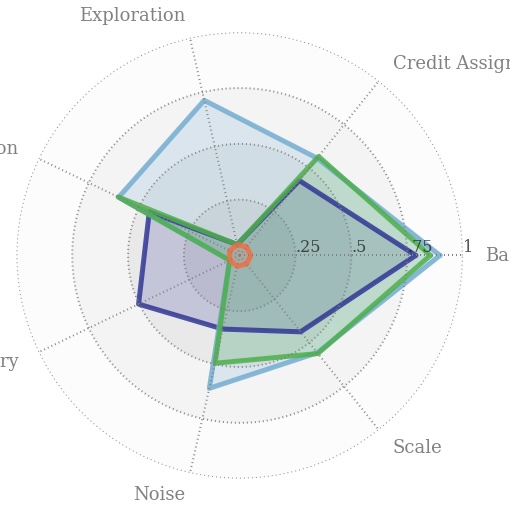
ICLR 2020 Spotlight
Methodical benchmark for the scaling properties of RL algorithms, with open source code.

Foundations and Trends in Machine Learning 2023
An elegant perspective on reinforcement learning through the lens of information theory.
Follow the links below.
Or, check out my CV.